ūāÖÓĮM║Ž─Żą═į┌Š░ė^╦«¾w╦«┘|─ŻöMųąĄ─æ¬ė├
ųąć°╬█╦«╠Ä└Ē╣ż│╠ŠW ĢrķgŻ║2015-10-21 8:29:47
╬█╦«╠Ä└Ē╝╝ąg | ģRŠ█╚½Ū“Łh▒Ż┴”┴┐Ż¼ĮĄĄ═Ų¾śIų╬╬█│╔▒Š
ĪĪĪĪŠ░ė^╦«¾w┤¾ČÓöĄČ╝╩Ūņoų╣╗“š▀┴„äėąį▌^▓ŅĄ─ŠÅ┴„╦«¾wŻ¼ūįā¶─▄┴”▓ŅŻ¼ęū│÷¼F╦«¾wĄ─╬█╚Š║═Ė╗ĀIB╗»[1]ĪŻŠ░ė^╦«¾wĄ─╦«┘|─ŻöM┼cŅA£y─▄×ķ╦«┘|įuār、╦«¾wĖ╗ĀIB╗»┼c╬█╚ŠĄ─┐žųŲęį╝░╦«ŁhŠ│╣▄└ĒęÄäØĄ╚╠ß╣®┐ŲīWĄ─ę└ō■[2]ĪŻ
ĪĪĪĪį┌╦«┘|─Żą═ųąŻ¼┤µį┌ų°ā╔ĘNīW┴Ģą═─Żą═:╚╦╣ż╔±ĮøŠWĮj║═ų¦│ųŽ“┴┐ÖC─Żą═ĪŻ╚╗Č°Ż¼▀@ā╔ĘN─Żą═Č╝┤µį┌ų°ę╗Č©Ą─ŠųŽ▐ąį║═╚▒³cŻ¼╚ń╗∙ė┌Įø“×’LļUūŅąĪ╗»Ą─╚╦╣ż╔±ĮøŠWĮj╩Ūę╗ĘNį┌æ¬ė├║═įć“×ųąĮ©┴óĄ─åó░l╩ĮĘĮĘ©Ż¼┐╔─▄│÷¼FŠų▓┐ūŅā×[3]ĪŻČ°╗∙ė┌ĮYśŗ’LļUūŅā×╗»Ą─ų¦│ųŽ“┴┐ÖCĘĮĘ©į┌╠Ä└Ē┤¾ęÄ─ŻĄ─śė▒ŠĢrŻ¼═∙═∙ąĶę¬Ū¾ĮŌÅ═ļsĄ─Č■┤╬ęÄäØå¢Ņ}Ż¼ėŗ╦ŃÅ═ļs[4]ĪŻ
ĪĪĪĪĮM║ŽŅA£y╩Ūė╔BatesĄ╚[5]ė┌1969─Ļ╠ß│÷Ą─ę╗ĘNŅA£yĘĮĘ©Ż¼įōĘĮĘ©į┌│õĘų└¹ė├Ė„éĆå╬ę╗ŅA£y─Żą═ā׳cĄ─╗∙ĄA╔ŽŻ¼─▄┐╦Ę■å╬ę╗─Żą═Ą─ŠųŽ▐ąį║═╚▒³cŻ¼▓óūŅĖ▀ą¦┬╩Ąž└¹ė├┼c═┌Š“öĄō■ą┼ŽóŻ¼ę“Č°▒╗ÅVĘ║Ąžæ¬ė├ė┌╦«ŁhŠ│ŅIė“[6-9]ĪŻ╚╗Č°Ż¼īŹļHŪķør═∙═∙╩ŪĖ„å╬ę╗─Żą═╩ŪĢrķgĄ╚ę╗ŽĄ┴ąūįūā┴┐Ą─║»öĄŻ¼į┌▓╗═¼Ģr┐╠─Żą═ūā╗»ę▓▓╗ŽÓ═¼Ż¼╦∙ęį╣╠Č©ÖÓųžĄ─Ęų┼õĘĮ╩Įūį╚╗¤oĘ©¾w¼F▀@ĘNĻPŽĄĪŻČ°ūāÖÓųžĮM║ŽŅA£y─Żą═Ż¼╠ß│÷ÖÓųžļSĢrķgĄ╚ę╗ŽĄ┴ąūįūā┴┐Č°ūā╗»Ą─╦╝ŽļŻ¼▒▄├Ō╣╠Č©ÖÓųžĄ─▒ūČ╦[10]ĪŻ╦∙ęįŻ¼▒Š╬─▓╔ė├╗∙ė┌╔±ĮøŠWĮj┼cų¦│ųŽ“┴┐ÖC2ĘN─Żą═Ż¼Į©┴óÖÓųžļSĢrķgĄ╚ę╗ŽĄ┴ąūįūā┴┐Č°ūā╗»Ą─ūāÖÓĮM║Ž─Żą═Ż¼üĒæ¬ė├ė┌Š░ė^╦«┘|Ą─╦«┘|─ŻöM┼cŅA£yĪŻ
ĪĪĪĪ1 ūāÖÓĮM║Ž─Żą═
ĪĪĪĪ1.1 ╔±ĮøŠWĮj─Żą═╔±ĮøŠWĮj(artificialneuralnetworks)╩Ūė╔┤¾┴┐Ą─╚╦╣ż╔±Įøį¬ÅVĘ║Ąž▀BĮėČ°│╔Ż¼ė├ęį─ŻĘ┬╚╦─X╔±ĮøŠWĮjĄ─Å═ļsŠWĮjŽĄĮyĪŻBP(back-propagation)╔±ĮøŠWĮjŻ¼╝┤š`▓ŅĘ┤Ž“é„▀fĄ─╔±ĮøŠWĮjŻ¼╩Ūīó▌ö│÷š`▓Ņęį─│ĘNą╬╩Į═©▀^ļ[║¼īėŽ“▌ö╚ļīėųīėĘ┤é„Ż¼▓óīóš`▓ŅĘųöéĮoĖ„īėĄ─╦∙ėąå╬į¬Ż¼Å─Č°½@Ą├Ė„īėå╬į¬Ą─š`▓Ņą┼╠¢Ż¼┤╦š`▓Ņą┼╠¢╝┤ū„×ķą▐š²Ė„å╬į¬ÖÓųĄĄ─ę└ō■ĪŻÖÓųĄĮø▀^▓╗öÓĄ─ą▐š²Ż¼ūŅĮKĄ├ĄĮ┐╔ęįØMūŃę¬Ū¾Ą─BP╔±ĮøŠWĮj─Żą═[11]ĪŻ
ĪĪĪĪ1.2 ų¦│ųŽ“┴┐ÖC─Żą═ų¦│ųŽ“┴┐ÖC(supportvectormachine)╩Ūę╗ŅÉą┬ą═Ą─ÖCŲ„šZčįŻ¼╦³Š▀ėą═ĻéõĄ─ĮyėŗīW┴Ģ└Ēšō║═│÷╔½Ą─īW┴Ģąį─▄Ż¼─▄Ė∙ō■ėąŽ▐Ą─śė▒Šą┼Žóį┌─Żą═Ą─Å═ļsąį║═īW┴Ģ─▄┴”ų«ķgīżŪ¾ūŅ╝čš█ųįŻ¼ęįŪ¾½@Ą├ūŅ║├Ą─═ŲÅV─▄┴”[12]ĪŻī”ė┌ĘŪŠĆąįå¢Ņ}Ż¼ų¦│ųŽ“┴┐ÖCĄ─╗∙▒Š╦╝Žļ╩Ū═©▀^ę╗éĆĘŪŠĆąįė│╔õīóöĄō■ė│╔õĄĮĖ▀ŠS╠žš„┐šķgŻ¼▓óį┌▀@éĆ┐šķg▀MąąŠĆąį╗žÜw[13]ĪŻ
ĪĪĪĪ1.3 ūāÖÓĮM║Ž─Żą═ūāÖÓĮM║Ž─Żą═Ż¼Ųõ║╦ą─Š═╩Ū┤_Č©Ė„éĆ─Żą═į┌Ė„éĆĢr┐╠╦∙š╝Ą─ÖÓųžŻ¼Å─Č°╩╣─Żą═Ė³║├ĄžĘ¹║ŽīŹļHŪķørĪŻī”ė┌méĆå╬ę╗ŅA£y─Żą═Ą├ĄĮĄ─ŅA£yųĄf1Ż¼f2Ż¼ĪŁŻ¼fmŻ¼▓╗Ę┴╝┘įO├┐ę╗éĆūįūā┴┐ī”æ¬ę╗éĆŽÓæ¬Ą─Ģr┐╠Ż¼ätŲõūāÖÓĮM║ŽŅA£y─Żą═×ķ:f(t) =”▓mi=1gi(t)fi(t) (1)╩Įųą:t=1Ż¼2Ż¼ĪŁŻ¼n;i=1Ż¼2Ż¼ĪŁŻ¼m;fi(t)×ķĄ┌iéĆ─Żą═į┌tĢr┐╠Ą─ŅA£yųĄ;gi(t)×ķĄ┌iéĆ─Żą═į┌tĢr┐╠Ą─ÖÓųžŻ¼ŲõØMūŃ:1=”▓mi=1gi(t) (2)╝┘įOgi(t)×ķtĄ─▀B└m║»öĄŻ¼ätgi(t)┐╔ęįė├p┤╬ČÓĒŚ╩ĮüĒ▒Ē╩Š:gi(t) =gi0Īżt0 +gi1Īżt1 +gi2Īżt2 +ĪŁ +gipĪżtp(3)ät:f(t) =”▓mi=1gi(t)fi(t) =[f1(t)Ż¼f2(t)Ż¼ĪŁŻ¼fm(t)]g10 g11 ĪŁ g1pg20 g21 ĪŁ g2pĪŁ ĪŁ ĪŁ ĪŁgn0 gn1 ĪŁ g©”©║©║©║©║ë©┤©▓©▓©▓©▓ûnpt0t1ĪŁt©”©║©║©║©║ë©┤©▓©▓©▓©▓ûn=”ż F(t)GT(t) (4)ę╗Ą®gi(t)ČÓĒŚ╩ĮĄ─┤╬öĄp┤_Č©Ż¼Š═┐╔ęį═©▀^ÅV┴x─µŠžĻćĄ─裣hĄ³┤·Ę©[10]üĒŪ¾ĮŌŽĄöĄŠžĻćGŻ¼▓ó┤_Č©ūŅĮKĄ─ūāÖÓĮM║ŽŅA£y─Żą═ĪŻ═¼ĢrŻ¼Å─ŽĄöĄŠžĻćGĄ─Ū¾ĮŌ▀^│╠ųą┐╔ęį░l¼FŻ¼ūāÖÓųžĮM║ŽŅA£yĘĮĘ©ŲõīŹŠ═╩ŪĖ∙ō■méĆå╬ę╗ŅA£y─Żą═į┌Ū░néĆĢr┐╠Ą─ŅA£yųĄüĒ┤_Č©─│éĆĢr┐╠(─│éĆūįūā┴┐)Ą─ÖÓųžųĄŻ¼Å─Č°Ą├ĄĮūāÖÓĮM║ŽŅA£y─Żą═Ą─ŅA£yųĄĪŻ
ĪĪĪĪ2 īŹ└²Ęų╬÷
ĪĪĪĪ2.1 ╗∙▒Š┘Y┴Ž▒Š╬─▀x╚Ī╠ņĮ“╩ą─│ł@ģ^Ą─Š░ė^╦«¾wū„×ķ蹊┐ī”Ž¾Ż¼įōŠ░ė^╦«¾wĄ─╦«├µ├µĘe╝s×ķ29000m2Ż¼ŲĮŠ∙╔ŅČ╚×ķ3.6mŻ¼┐é╚▌Ęe╝s×ķ10500m3Ż¼ī┘ė┌Ąõą═Ą─│Ū╩ąĘŌķ]ŠÅ┴„╦«¾wĪŻ╦«┘|▒O£y³c╬╗ė┌╦«¾wų„¾w╦«ė“ĄžÄ¦Ż¼▒O£yĢrķgÅ─2012─Ļ7į┬ĄĮ2013─Ļ11į┬Ż¼╣▓▒O£yöĄō■śė▒Š×ķ35éĆŻ¼▒O£yųĖś╦░³└©╦«£ž、pHųĄ、░▒Ą¬、┐饬、┐é┴ū║═╗»īWąĶč§┴┐(COD)Ą╚╦«┘|ųĖś╦ĪŻ
ĪĪĪĪCODū„×ķę╗ĘN▒Ēš„╦«¾wėąÖC╬’║¼┴┐┤¾ąĪĄ─ųžę¬ųĖś╦Ż¼į┌ę╗Č©│╠Č╚╔Ž┐╔ęį▒Ē╩ŠŠ░ė^╦«¾wĄ─╦«┘|ĀŅør║═╦«¾wĄ─╬█╚ŠŪķørĪŻę“┤╦Ż¼▒Š╬─Į©┴óCOD┼cĢrķg、╦«£ž、pHųĄ、░▒Ą¬、┐饬║═┐é┴ūų«ķgūā╗»ĻPŽĄĄ─╦«┘|─Żą═Ż¼═©▀^CODĄ─ūā╗»üĒ┴╦ĮŌ«öŪ░Š░ė^╦«¾w╦«┘|ĀŅørŻ¼▓ó×ķ╦«┘|Ą─ŅA£yŅAŠ»ū„│÷┐ŲīWĄ─┼ąöÓ┼cĘų╬÷ĪŻ
ĪĪĪĪ2.2 BP╔±ĮøŠWĮj─Żą═▒Š╬─└¹ė├įōŠ░ė^╦«¾wÅ─2012─Ļ7į┬ĄĮ2013─Ļ11į┬Ą─▒O£yöĄō■Ż¼Į©┴óBP╔±ĮøŠWĮj╦«┘|─Żą═ĪŻė╔ė┌Ė„éĆ╦«┘|▒O£yųĖś╦ųĄĄ─┴┐ŠV╝░öĄ┴┐╝ē▓╗═¼Ż¼į┌BP╔±ĮøŠWĮjė¢ŠÜŪ░ꬎ╚ī”įŁ╩╝╦«┘|öĄō■▀MąąÜwę╗╗»╠Ä└Ē[14]Ż¼╩╣Ą├Ė„éĆųĖś╦ųĄ┬õį┌[0Ż¼1]ų«ķgĪŻī”ė┌Üwę╗╗»ĘĮ│╠Ż¼▌ö╚ļĢrķgtŻ¼╩Ūęį2012─Ļ7į┬28╠¢×ķĄ┌1╠ņŻ¼ęį║¾Ė„éĆ▒O£yĢrŲ┌Ą─Ģrķg×ķīŹļH▒O£y╚šŲ┌┼c7į┬28╠¢Ą─ĢrķgŠÓļxŻ¼å╬╬╗×ķ╠ņĪŻ╚╗║¾į┘īó▌ö╚ļĢrķg、╦«£ž、pHųĄ、░▒Ą¬、┐饬、┐é┴ū║═CODųĄ▓╔ė├Üwę╗╗»╣½╩Į(5)▀Mąą╠Ä└ĒŻ¼╣½╩Į╚ńŽ┬:Xi = xi-xmin xmax -xmin(5)╩Įųą:xmin×ķįŁ╩╝▒O£yųĄĄ─ūŅąĪųĄ;xmax×ķįŁ╩╝▒O£yųĄĄ─ūŅ┤¾ųĄ;xi×ķĄ┌iéĆįŁ╩╝▒O£yųĄ;Xi×ķÜwę╗╗»╠Ä└Ēų«║¾Ą─Ą┌iéĆ▒O£yųĄ;
ĪĪĪĪī”ė┌Į©┴óĄ─BP╔±ĮøŠWĮj─Żą═Ż¼▌ö╚ļ┴┐░³└©Ģrķg、╦«£ž、pHųĄ、░▒Ą¬、┐饬║═┐é┴ūŻ¼▌ö│÷┴┐×ķCODŻ¼ļ[║¼īėĄ─╔±Įøį¬▓╔ė├Sigmoidą═ūāōQ║»öĄŻ¼▌ö│÷īėät▓╔ė├ŠĆąįūāōQ║»öĄĪŻČ°ī”ė┌╔±ĮøŠWĮjĮYśŗųąĄ─Ė„éĆģóöĄ┤_Č©ät└¹ė├īW┴ĢĢrķg▌^Č╠、Š½Č╚┼c╩šö┐ąį▌^║├Ą─L-__M╦ŃĘ©Ż¼ļ[║¼īėĄ─╣سcöĄ[15]ätĖ∙ō■╣½╩Į(6)┤_Č©:Ny =(Ns +Nj)0.5 +N (6)╩Įųą:Ny ×ķļ[║¼īėĄ─╣Ø═¼ĢrŻ¼īóŠ░ė^╦«¾w╦«┘|▒O£yśė▒ŠĄ─öĄō■Ęų×ķė¢ŠÜ╝»、Öz“×╝»ā╔éĆ▓┐ĘųĪŻė├ė¢ŠÜ╝»üĒė¢ŠÜ┼cöM║ŽBP╔±ĮøŠWĮjŻ¼ė├Öz“×╝»üĒī”─Żą═Ą─ŅA£yĮY╣¹▀MąąÖz“×ĪŻ▒Š─Żą═ųąīóŪ░3/4Ą─Üwę╗╗»Ą─öĄō■ū„×ķBP╔±ĮøŠWĮjĄ─ė¢ŠÜ╝»Ż¼ė├║¾1/4Ą─īŹļH▒O£yųĄū„×ķBP╔±ĮøŠWĮj─Żą═Ą─Öz“×╝»ĪŻ└¹ė├MATLABųąĄ─BP╔±ĮøŠWĮj╣żŠ▀ŽõŻ¼╚Īė¢ŠÜĄ─ūŅ┤¾čŁŁh┤╬öĄepochs=10000Ż¼ąį─▄║»öĄgoal=0Ż¼ūŅ┤¾“×ūCöĄō■╩¦öĪĄ─┤╬öĄmax_fail=20Ż¼ūŅąĪĄ─ąį─▄╠▌Č╚ųĄmingrad=0.00001ĪŻ▀Mąą▓╗öÓĄžš{įćŻ¼░l¼Fį┌N=2Ż¼╝┤ļ[║¼īėĄ─╣سcöĄNy×ķ4ĢrŻ¼─Żą═╩šö┐ąįūŅ║├ĪŻ─Żą═ĮY╣¹┼cīŹļH▒O£yųĄĄ─▒╚▌^╚ńłD1╦∙╩ŠĪŻŠ▀¾wģóęŖhttp://www.jianfeilema.cnĖ³ČÓŽÓĻP╝╝ąg╬─ÖnĪŻ
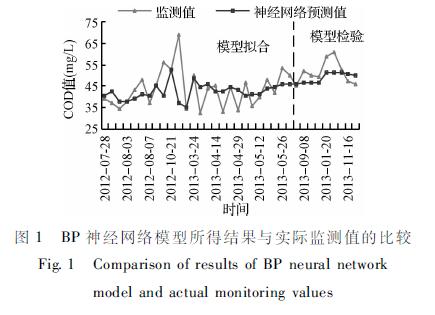
įöŪķšłŽ┬▌dŻ║ūāÖÓĮM║Ž─Żą═į┌Š░ė^╦«¾w╦«┘|─ŻöMųąĄ─æ¬ė├

